1. Datenbanken:
Im Folgenden sollen die für weiteren ontologisch-philosophischen Betrachtungen
relevanten Aspekte von Datenbanken erörtert werden. Es geht also bewusst
nicht um technische Details oder konkrete Datenbankrealisierungen, sondern
um theoretische Grundlagen und Konzepte, welche helfen sollen einen Eindruck
der den Datenbanken zugrunde liegenden ontologischen Modelle zu erhalten.
Was ist eigentlich eine Datenbank? Eine Datenbank dient dazu Daten in
elektronischer Form abzuspeichern, um zu einem späteren Zeitpunkt
auf diese Daten wieder zugreifen zu können. Es handelt sich also -
vereinfacht betrachtet - um eine Karteikartensammlung im Computer. Daten
sind in diesem Zusammenhang abstrakte und strukturierte Teile einer Beschreibung
der Welt (oder zumindest einer möglichen Welt), wobei sich die Welt
aus sogenannten Sachverhalten zusammensetzt. Diese Sachverhalte werden
mit Sätzen beschrieben. Normalerweise sind nur Sätze von Interesse
die wahr sind - sogenannte Tatsachen -, also bestehende Sachverhalte beschreiben.
Es steht allerdings jedermann frei auch nicht bestehende Sachverhalte in
eine Datenbank abzubilden.
Die Form der Beschreibung, der Grad der Abstraktion bzw. die Struktur
hängt von folgenden Aspekten ab:
-
dem Datenbankprogramm
-
dem Datenbankprogrammierer
-
denjenigen die Daten in die Datenbank eingeben
-
denjenigen die Daten aus der Datenbank abfragen
1.1. Komponenten einer Datenbank:
Der Begriff Datenbank als Überbegriff setzt sich aus mehreren Einzelteilen
zusammen (siehe dazu Abbildung 1.1) :
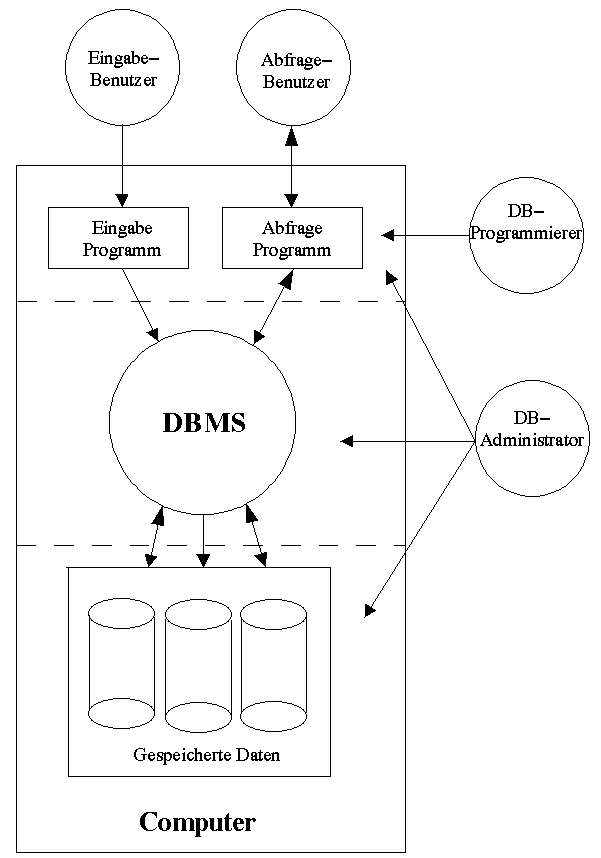
Abb.1.1: Überblick über die einzelnen Komponenten einer Datenbank.
1.1.1. Benutzer:
Dieser hat normalerweise ein Problem mit der Komplexität oder dem
Umfang gewisser Aufgaben. D.h. er/sie arbeitet mit Informationen - die
Sachverhalte beschreiben - die einerseits nicht ohne weiteren Aufwand einfach
gemerkt werden können, oder andererseits mit anderen Mitmenschen des
öfteren geteilt werden müssen. Eine Möglichkeit wäre
nun mit analogen Methoden (wie Karteikarten) die Informationen zu erfassen.
Dies bringt aber meist Probleme wenn Daten, auch über weite Distanzen,
von mehreren Personen benutzt werden sollen. Auch die oben angesprochene
Komplexität bzw. der Umfang der zu behandelnden Daten und Datenabfragen
setzt einer solchen Methode Grenzen, besonders was das Suchen in den Daten
betrifft. Somit wird vom Benutzer die Forderung nach leistungsfähigeren
Hilfsmittel kommen.
Ist die Datenbank erst einmal im Einsatz ist es Aufgabe des Benutzers
bei der Eingabe von den Sachverhalten zu den Daten zu abstrahieren und
nach der Abfrage die erhaltenen Daten so zu interpretieren, dass wieder
Beschreibungen von Sachverhalten entstehen.
1.1.2. Datenbank-Analytiker/Programmierer:
Der Datenbank-Analytiker/Programmierer ist im Normalfall nicht der, der
das "Database Management System", kurz DBMS, programmiert, sondern
folgende Aufgaben übernimmt: Zuerst analysiert der Datenbank-Analytiker/Programmierer
die Benutzerwünsche und versucht herauszufinden welche Informationsteile
der Sachverhaltsbeschreibung der Benutzer wirklich verwenden möchte
und auf welche Art und Weise dieser auf diese Informationen zugreifen möchte.
Sowohl die Art der Information als auch die Art der Abfragen bestimmt nun
das Datenmodell welches als Abstraktion des Sachverhalts entworfen wird.
Wenn noch nicht entschieden wurde welches Datenbankmodell verwendet wird,
kann aufgrund der Analyse auch ein entsprechendes Datenbankmodell ausgewählt
werden. In jedem Fall hat aber das Datenbankmodell ebenfalls Einfluss auf
das Datenmodell, also die Art und Weise wie die Sachverhalte mit Daten
modelliert werden. Der Datenbank-Programmierer bettet danach die Daten
in eine zu definierende Struktur. Diese Struktur wird wiederum vom Datenbankmodell
und der Art zukünftiger Abfragen bestimmt. Als nächstes werden
Programmmodule erstellt welche die Eingabe und Abfrage von Daten, möglichst
den Kundenbedürfnissen entsprechend, ermöglichen.
1.1.3. Datenbank Administrator:
Der Datenbank-Administrator ist für die Integrität der gespeicherten
Daten zuständig. Er betreut und wartet sowohl die gespeicherten Daten
als auch das "Datenbank Management System" sowie die Eingabe- und Abfragemodule,
ohne aber notwendiger Weise zu wissen welche Sachverhalte durch die gespeicherten
Daten beschrieben werden bzw. wie die Daten zu interpretieren sind.
1.1.4. Eingabe- und Abfrage-Programmmodule:
Diese Programmmodule dienen der vereinfachten und benutzerfreundlichen
Eingabe bzw. Abfrage von Daten. Das "Datenbank Management System" besitzt
zwar normaler Weise eine Schnittstelle um Daten sowohl eingeben als auch
abrufen zu können. Dazu ist es aber nötig die genaue Syntax (und
Semantik) einer speziellen Datenbanksprache (z.B. SQL: Structured Query
Language) zu kennen. Meist wird sowohl für die Eingabe als auch
für die Abfrage sowie für die Darstellung der Ergebnisdaten einer
Abfrage ein Formular am Bildschirm verwendet, in welches die bereits abstrahierten
Daten einzugeben sind bzw. angezeigt werden. Es gibt aber auch Tendenzen,
wo natürlichsprachliche Sachverhaltsbeschreibungen für Eingabe,
Abfrage wie Ausgabe verwendet werden können. Diese Systeme sind derzeit
aber noch im Entwicklungsstadium. Geschrieben werden können solche
Programmmodule mit nahezu jeder beliebigen Programmiersprache, solange
das verwendete Datenbanksystem ein Interface für diese Sprache anbietet.
Ein solches Interface transformiert dann die Datenformate der Datenbank
in die Datenformate der verwendeten Programmiersprache und umgekehrt.
1.1.5. Datenbank Management System (DBMS):
Das "Datenbank Management System" (in weiteren kurz DBMS) ist jener Programmteil
der für die Kommunikation zwischen Benutzer (im allgemeinen Sinn;
also auch Datenbankprogrammierer, Datenbank-Administrator,...) und dem
Computersystem mit den gespeicherten Daten zuständig ist. Das DBMS
hat somit einen wesentlichen Einfluss darauf wie Daten tatsächlich
im Computer gespeichert werden. Ebenso hängt vom DBMS ab wie Elementarsätze
strukturiert, zerlegt und zu Daten abstrahiert werden. Das DBMS bestimmt
die Grundkonzepte des ontologischen Modells, welche verwendet werden um
eine abstrakte Beschreibung der Welt im Computer abzubilden. Dazu gibt
es mindestens eine - meist aber mehrere - Datenbanksprache mit welcher
mit dem DBMS kommuniziert werden kann und somit die Datenbank entsprechend
den individuellen Beschreibungen konfiguriert werden kann. Auch für
die Abfrage von Daten ist das DBMS zuständig. Die Datenbanksprache
bestimmt somit nicht nur die Struktur und Art der Eingabedaten sondern
auch die Möglichkeit zu einem späteren Zeitpunkt wieder auf diese
Daten zugreifen zu können.
Moderne DBMS lassen sich vom Benutzer seinen Bedürfnissen entsprechend
erweitern, was sich dann ebenso in einer Erweiterung der Semantik der Datenbanksprache
niederschlägt.
1.1.6. Gespeicherte Daten:
Bei den gespeicherten Daten handelt es sich um die physikalisch auf der
Festplatte (oder anderen Speichermedien) abgespeicherten Rohdaten. Diese
sind meist in ein binäres Schema, welches vom Datenbanksystem vorgegeben
wird, eingebettet, sodass die ursprünglich eingegebenen Daten nicht
mehr direkt (mittels der Systemsoftware), also ohne Umweg über das
DBMS gelesen oder manipuliert werden können.
1.1.7. Der Computer:
Die Hardware und die Systemsoftware, auf denen das DBMS läuft, wird
von diesem verwendet um Daten physikalisch auf dem Speichermedium abzuspeichern
und von dort wieder einzulesen. Dabei handelt es sich meist um sehr einfache
Input-/Output-Operationen wo ganze Dateien vom Computersystem an das DBMS
übergeben werden, bzw. vom DBMS an das Computersystem zurückgegeben
werden um diese wieder abzuspeichern. Aus Leistungsgründen umgehen
manche DBMS Teile der Systemsoftware und greifen direkt auf die Hardware
zu. Natürlich hat sowohl Hardware als auch Systemsoftware einen mehr
oder weniger grossen Einfluss auf die Konzeption des DBMS und somit auf
die Art und den Grad der Abstraktion der Daten. Da aber moderne Computersysteme
eine sehr ähnliche System-Architektur besitzen funktionieren die meisten
Datenbanken auf verschiedenen Systemen mit für den Benutzer nahezu
gleichem Verhalten.
Wesentliche Änderungen bei den Computersystemen (z.B. Multiprozessorsysteme,
holographische Speichermedien, Quantencomputing) haben aber normalerweise
einen mehr oder weniger grossen Einfluss auf die Konzeption neuer Datenbanken
und somit auch auf das ontologische Modell das diesen Konzepten zugrunde
liegt.
Moderne Betriebssysteme inkludieren bereits gewisse Datenbankfunktionalitäten
in ihren Basis-Funktionsumfang (Indexerstellung, Recordmanagement, ...)
was den Gedanken nahe legt, dass es sich bei (solchen) Computersystemen
eigentlich nur um Datenbankmaschinen handelt.
1.2. Der Abstraktionsprozess:
Bei den Sachverhalten kann es sich um Teile
der wirklichen Welt oder um Teile einer virtuellen (möglichen) Welt
(es könnte z.B. ein Schriftsteller Beschreibungen seiner Romanfiguren
in einer Datenbank ablegen) handeln. Normalerweise sind im Zusammenhang
mit Datenbanken nur Sachverhalte von Interesse die auch bestehen - es ist
meist nur relevant was ist und nicht was nicht ist (manche Datenbanken
verwenden sogar das Konzept, dass alles was nicht in der Datenbank abgebildet
wurde automatisch als falsch oder nicht bestehender Sachverhalt interpretiert
wird; siehe dazu weiter unten bei deduktiven datenbanken). Sachverhalte
werden mittels Sätzen beschrieben. Bestehende Sachverhalte werden
nur durch wahre Sätze beschrieben (das ist gewissermaßen die
Definition wahrer Sätze). Man hat aber natürlich die Freiheit
auch jede andere Art von Sätzen hier zu verwenden (falsche, unsinnige,...),
jedoch würde das die Verwendbarkeit der in der Datenbank abgelegten
Daten für andere Personen wesentlich erschweren.
Die Sätze werden zuerst aufgespaltet und umgeformt sodass eine
möglichst einfache und einheitliche Form der Beschreibung entsteht.
Diese Form hängt stark von der Art und der Struktur der verwendeten
Datenbank ab. Die so gewonnenen Sätze (Elementar-Sätze) werden
nun in Satzbausteine zerlegt, also ihrer Syntax entkleidet.
Dieser Prozess wird auch als semantische Modellierung bezeichnet. Einer
der weitest verbreiteten Modelle stellt das "Entity/Relationship"-Modell
dar. Dabei wird eine natürlichsprachige Beschreibung nach folgenden
semantischen Konzepten, die sich bei der Beschreibung der Wirklichkeit
als nützlich herausgestellt haben, analysiert: es gibt also so etwas
wie Dinge oder eben Entitäten, welche nach Typen geordnet werden können.
Diese Entitäten besitzen gewisse Eigenschaften, welche für alle
Entitäten eines bestimmten Typs gleich sein sollen (somit den Typ
definieren). Jede Entität ist etwas einmaliges und kann eindeutig
identifiziert werden; man könnte auch von Identität sprechen.
Und Entitäten können in bestimmten Zusammenhängen bzw. Verbindungen
- den sogenannten "relationaships"- mit anderen Entitäten stehen.
Hat man diese semantischen Grundbausteine erst einmal identifiziert kann
man davon ein Datenmodell erstellen, auf das sich dieses semantische Modell
optimal abbilden läßt (dass als Folge der "Entity/Relationship"-Analyse
sogenannte Datenobjekte, Integritätsregeln und Operatoren festgelegt
werden soll hier nur der Vollständigkeit halber erwähnt werden).
Man könnte auch sagen, dass die Satzbausteine als Daten interpretiert,
d.h. in eine für die Datenbank geeignete Form umgewandelt werden.
Diese Daten, also die Abbildung der abstrakten Satzbausteine in der Datenbank,
sind die kleinsten Teile einer Datenbank aus Benutzersicht, also sozusagen
Elementarbausteine. Intern werden diese Daten vom DBMS noch in Rohdaten
umgewandelt und danach dem Computerbetriebssystem übergeben das diese
Rohdaten als Binärdaten mittels der Systemsoftware in der Computerhardware
ablegt.
Alle zu einem (Elementar-)Satz gehörenden Satzbausteine bilden
einen Datenbankeintrag oder Datensatz.
Meist werden dann diese Datenbankeinträge, das sind die abstrahierten
Teile von Sätzen mit gleichem Aufbau, also gleichen Satzbausteinen,
in einem Teil der Datenbank gesammelt um zu einem späteren Zeitpunkt
aus diesen Teil einen oder mehrere Datensätze nach bestimmten Suchkriterien
auszuwählen.
Mittels des DBMS kann auf die gesammelten (Binär-)Daten bei einer
späteren Abfragen oder Änderungen wieder über die Systemsoftware
zugegriffen werden.
Einen Überblick über die verschiedenen Abstraktionsebenen
mit einem einfachen Beispiel findet sich in folgender Aufstellung:
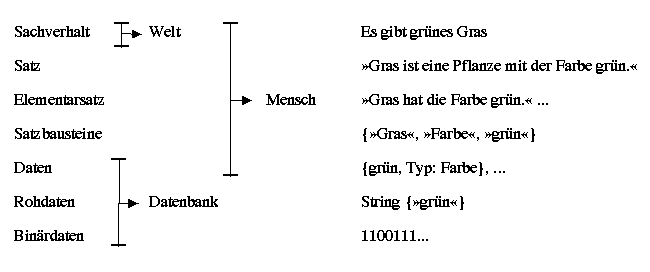
Bei der Abfrage von Daten aus einer Datenbank wird der umgekehrte Prozess
in die Wege geleitet, wobei der Schritt von den Binärdaten über
die Rohdaten hin zu den Daten vom DBMS (bzw. der Systemsoftware) reversibel
erledigt wird. Ob der Konkretisierungsschritt von den Daten hin zu den
Satzbausteinen, den Elementarsätzen und zum Satz ebenfalls gelingt,
hängt sehr vom Design der Datenbank und dem Abstraktionsgrad der Daten
ab. D.h. je stärker bei der Eingabe der Daten vom Satz her abstrahiert
wird, desto schwieriger wird es werden die Daten richtig zu interpretieren,
sodass sich daraus wieder der entsprechende Sachverhalt identifizieren
lässt.
©Mag.Dr. Alfred Hofstadler : "Datenbanken und
Wittgenstein: ontologische Vergleiche",Diplomarbeit an der Universität
Wien, März 2001.