Bei dieser Arbeitsweise wird versucht die deskriptiven Möglichkeiten
der natürlichen Sprache weitgehendst zu erhalten und zu verwenden.
Am Anfang steht eine objektorientierte Analyse der natürlichsprachigen
Problem- und Lösungsbeschreibung. Dabei gibt es mehrere methodische
Ansätze, wobei eine Möglichkeit die bereits bekannte Entity-Relation-Analyse,
angereichert um einige weiter Analyseaspekte wie z.B. Vererbungsrelationen,
darstellt. Im ersten Analysegang wird dabei die natürlichsprachige
Problem- und Lösungsbeschreibung nach Substantiven, Adjektiven und
Verben durchsucht, wobei die Substantive den Objekten entsprechen, die
Adjektive können meist als Datenelemente der Objekte umgesetzt werden
und die Verben werden zu Methoden (zur genauen Begriffsbestimmung siehe
unten). Erst nachdem diese Grundbausteine identifiziert sind setzen
komplexere Analysemethoden ein, die die genauen Abhängigkeiten und
Relationen zwischen den einzelnen Elementen bestimmen lassen.
Ziel ist es, das Niveau der Abstraktion bei der Beschreibung des Problems
in der Datenbank - bzw. in der Klasse (siehe unten),
also im objektorientierten Programm - möglichst nahe der natürlichen
Sprache zu halten. Es soll somit nur ein absolutes Minimum an Abstraktion
eingeführt werden, um dem Programmierer zu ermöglichen eine Beschreibung
des Problems im Programm umzusetzen, die möglichst nah an der natürlichsprachigen
Problembeschreibung liegt. Andererseits soll der Abstraktionsgrad hinsichtlich
der physischen Repräsentation der Daten im Computer möglichst
groß sein. Der Programmierer, bzw. Anwender soll sich keine Gedanken
machen müssen wie die Daten im Endeffekt abgespeichert werden. Ihn
soll einzig und allein ein möglichst aussagekräftiges Datenmodell
interessieren.
Beim objektorientierten Design wird versucht eine optimierte Abbildungen
der Wirklichkeit zu erreichen: optimiert in dem Sinne, dass sprachliche
Ungenauigkeiten oder Sinn- bzw. Bedeutungslosigkeiten durch die Analyse
eliminiert wurden. Da aber keine zusätzliche Sprache eingeführt
wird in die die natürliche Sprache abgebildet werden muss, kann eine
nahezu verlustfreie Übertragung der Aussagen der natürlichen
Sprache in ein objektorientiertes Programm erreicht werden (dies ist eine
stark idealisierte Sichtweise, und stösst im wirklichen Leben rasch
an ihre Grenzen).
Anmerkung: An dieser Stelle muss zwischen Anwendungsprogrammierer und
"Klassenprogrammierer" unterschieden werden. Der Anwendungsprogrammierer
kann natürlich nur dadurch auf eine semantisch sehr reiche Sprache
zurückgreifen, da ein "Klassenprogrammierer" die objektorienterte
Sprache bzw. Datenbank um die für die Problembeschreibung/Lösung
notwendigen Klassen (siehe unten) zuvor angereichert
hat. Der Klassenprogrammierer erzeugt mit den Klassenbibliotheken eine
semantische Erweiterung der eigentlichen Programmiersprache, sodass diese
neue Programmiersprache (Programmiersprache + Klassenbibliotheken) eine
semantische Reichhaltigkeit anbieten, die der Semantik der natürlichen
Sprache, bezogen auf einen eng begrenzten Problemkontext, sehr nahe kommt.
Diese Klassen können aber auch für andere Problembeschreibungen
dann wiederverwendet, oder adaptiert werden, sodass nach Erstellung ausreichend
komplexer Klassenbibliotheken eine Bearbeitung eines Problems ohne weitere
Veränderungen durch den Klassenprogrammierer, also nur durch den Anwendungsprogrammierer,
durchgeführt werden können. Klassenprogrammierer müssen
einen weit grösseren Abstraktionsgrad eingehen und im ungünstigsten
Fall bis auf die Maschinenebene zurückgehen. Prinzipien des objektorienten
Arbeitens (siehe unten) gewährleisten aber,
dass diese Implementierungsdetails keine wesentliche Auswirkung auf den
Anwendungsprogrammierer und seine Analyse haben.
Im Folgenden sollen einige Grundbegriffe der objektorientierten Analyse
bzw. Design erklärt werden. Diese sind:
ad 2.) Ein "Objekt" entsteht durch Instantiierung einer Klasse. Es wird also mit Hilfe des Bauplans ein reales Objekt erzeugt. Durch einen eindeutigen Namen und durch bestimmte Datenwerte erhält dieses Objekt eine eindeutige Identität. Bei reinen objektorientierten Sprachen sind alle Datentypen Klassen und somit gibt es nur Objekte als Daten. Und die einzige Möglichkeit diese Daten zu manipulieren ist, indem man Messages zu Objekte schickt bzw. von diesen empfängt. Es gibt somit auch keine Funktionsaufrufe mehr, wo in einer Funktion bestimmte Datenwerte manipuliert werden. Will ein Objekt eine bestimmte Information von einem anderen Objekt, dann sendet dieses erste Objekt eine Message an das zweite Objekt in dem es die gewünschten Informationen anfordert, und das zweite Objekt sendet wiederum eine Message zurück mit den gewünschten Informationen, falls diese geliefert werden können, oder sonst einer entsprechenden Fehlermeldung.
ad 3.) Diese Art Daten zu Manipulieren hat einen tieferen Grund, das "Information Hiding". Darunter versteht man, dass der Benutzer von Klassen keine Ahnung von der konkreten Implementierung einer Klasse haben muss. Er muss also nicht wissen welche abstrakten Datentypen in einer Klasse vorgesehen sind, oder wie eine bestimmte Methode auf solche Datenelemente zugreift. Für den Benutzer einer Klasse, also jenen der Objekte anlegt un mit diesen manipuliert ist es nur wichtig welche Messages die Objekte verstehen, also wie man mit den Objekten kommunizieren kann. Der Vorteil eines solchen Designs ist, dass man Implementierungen von Objekten beliebig verändern kann, solange nur die Messages, die das Objekt versteht sich nicht ändern. Man kann also in obigem Beispiel die Implementierung des Datenelements "Gewicht" von Integer auf Float (also von ganzer Zahl auf rationale Zahl) umstellen, solange das Verhalten der Methoden "Gewicht_eintragen" und "Gewicht_abfragen" nicht ändern. Dies hat den Vorteil, dass man Designprobleme oder -Fehler sehr einfach beheben kann, und auch das Verhalten von Objekten einfach an neue Anforderungen anpassen und erweitern kann.
ad 4.) Die "Vererbung" stellt einen weiteren wichtigen Aspekt
des objektorientierten Ansatzes dar. Dabei geht es darum Klassen in sogenannte
"ist-ein" Relationen zu bringen. So ist z.B. ein Mann ein Mensch, ein Mensch
ist ein Lebewesen, usw. Man erzeugt so eine Hierarchie von Klassen, die
von sehr konkreten zu immer abstrakteren Objekten geht. Die abstraktere
Klasse stellt hierbei immer den Elternteil ("parent") der konkreteren Klasse
dar, dem sogenannten Kind ("child"). Wichtig ist dabei, dass ein Kind alle
Eigenschaften der Elternklasse vererbt bekommt. Dass bedeutet, dass alle
Datenelemente und Methoden von der Elternklasse an das Kind weitergegeben
werden. Für die Erstellung einer Kindklasse bedeutet das, dass man
sich nicht mehr um die Aspekte der Klasse kümmern muss, die bereits
durch die Elternklasse abgedeckt werden. Ausserdem kann sich der Anwenderprogrammierer
darauf verlassen, dass in einer Klassenhierarchie alle konkreteren Klassen
(also jeweils die Kinder) mit all den Methoden der Elternklassen manipuliert
werden können. Das bedeutet, dass in einem bestehenden Programm ein
Objekt einer allgemeineren Ausprägung durch eine konkreter Instanz
ersetzt werden kann, ohne etwas am Programm ändern zu müssen.
Der Vollständigkeit halber soll erwähnt werden, dass ein Kind
auch von mehreren Elternklassen erben kann.
ad 5.) Unter "Polymorphismus" versteht man einerseits, dass ein
Objekt auf gleiche Messages, je nach Kontext sich unterschiedlich verhält,
und andererseits, dass man einem Objekt unter dem gleichen Messagenamen
unterschiedliche Messages senden kann. Im ersteren Fall kann man also bei
der Vererbung eine Methode, die vererbt wurde überschreiben und ihr
eine neue Bedeutung, eine an den spezifischeren Charakter des neuen Objekts
angepasste, verleihen. So kann in obigem Beispiel eine Methode Name (...)
für den Klassentyp Lebewesen den Typ des Lebewesen, also z.B. "Pferd",
"Vogel",..., liefern. Verwendet man die gleiche Methode beim Klassentyp
Mensch so liefert diese den Vornamen und Nachnamen des Menschen, also z.B.
"Ludwig Wittgenstein". Wird nun ein Objekt des Typs Mensch im Kontext eines
Lebewesens verwendet, so wird aber nicht die Methode Name(...) des Menschen
aktiviert sondern die des Lebewesen. Als Antwort würde man also z.B.
"Mensch" erhalten.
Im anderen Fall kann ein und die selbe Klasse mehrere Methoden gleichen
Namens besitzen - dazu ist keinerlei Vererbung notwendig -, die je nach
unterschiedlichen Parametern, also unterschiedlichen Messages, unterschiedlich
reagieren. Es könnte in obigem Beispiel eine Methode Gewicht_erhöhen
( "2x" ) und eine Methode Gewicht_erhöhen ( 17.5 ) geben. Erstere
würde eine Verdopplung des bestehenden Gewichts bewirken, die zweite
Methode würde z.B. 17.5 kg zum bestehenden Gewicht hinzuaddieren.
Einen Überblick über die wichtigsten Strukturen des objektorientierten
Ansatzes finden sich in Abbildung 4.1.
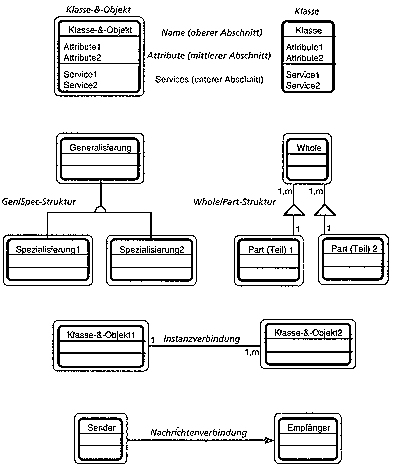
Abb. 3.1: Grafische Darstellung der wichtigsten Strukturen der objektorientierten
Analyse (aus COAD & YOURDON. 1994b).
Weitere Informationen zum Themenbereich Objektorientierte Analyse, Design
und Programmierung finden sich in COAD &
YOURDON 1994a, 1994b, COAD & NICOLA
1994, SCHÄFFER 1995 und in BLUM
1992.
Nach dieser kurzen Einführung in das objektorientierte Konzept
soll nun die Anwendung dieser Gedanken auf Datenbanken besprochen werden.